Welcome to lydxlx's Blog!
-
Xfinity Internet does NOT come with UNLIMITED data for free
I noticed the following statement when I was renewing my current xfinity internet plan.
Includes our xFI Gateway and all the benefits of xFi, plus
Unlimited data ($30/mo value) for peace of mind
The best WiFi coverage throughout your home, with an xFi Pod included if recommended
Hmm… After doing some research online, I found the evidence from my xfinity account usage page that the default internet monthly quota is 1.2TB, as shown in the following image.
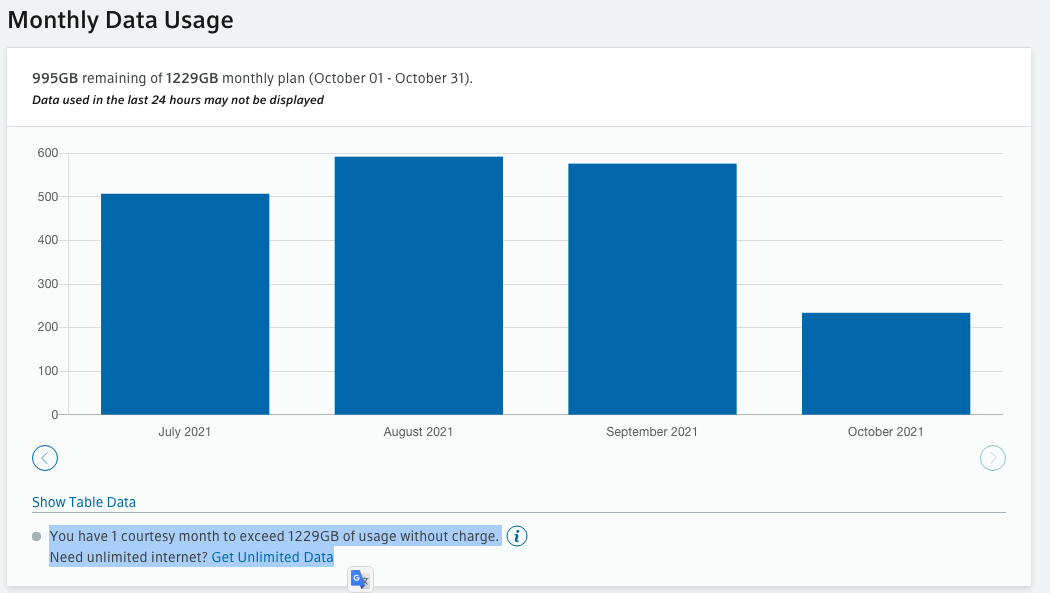
You have 1 courtesy month to exceed 1229GB of usage without charge.
After using 1 courtesy month, if you exceed the plan you will be charged $10.00 for each 50GB of additional data provided, but charges will not exceed $100 each month, no matter how much you use. You can also purchase our unlimited data option.Not too bad. But still, $10.00 for each 50GB of additional data provided seems just too high, even with the $100.0 additional dollar cap. So be mindful…
-
Union in SQL
Union in SQL performs implicit deduping on all the columns, which can cause certain bugs if not paying enough attention.
For example, the output of the following SQL will only return ONE row.
SELECT key FROM ( SELECT 1 AS key UNION ALL SELECT 1 AS key UNION ALL SELECT 1 AS key ) UNION SELECT key FROM ( SELECT 1 AS key UNION ALL SELECT 1 AS key UNION ALL SELECT 1 AS key )If we are using
UNION ALLinstead, the result will contain 6 rows instead.
-
Baby Wellness Guide at 9 Months Old
Safety & Child-proofing
- Dangling cords, hot liquids, tablecloths, appliances, plastic bags, electrical outlets, and stairs can all be dangerous to an exploring/curious baby.
- Keep household cleaners, vitamins, and medicines out of reach.
- Keep your baby safe with constant supervision during bath time and when on high surfaces such as changing tables, beds, and sofas.
- Avoid walkers. They can tip over and cause your baby harm.
- Be careful of small objects and powder: babies can choke on them. Small magnets and batteries, when swallowed, can cause serous internal injuries.
- Install the car seat in the back seat, rear-facing.
- Check to make sure smoke and carbon monoxide detectors are working.
- Avoid smoke/tobacco/cigarette/vaping liquid or smoke/marijuana exposure.
- Consider learning infant/child CPR.
- POISON CONTROL CENTER: 1-800-222-1222
Development
- Your assertive baby is on the move. Your baby can sit and play, but may also be scooting/crawling, pulling up to a stand, and “cruising”.
- Your child can pick up small objects between their thumb and index finger (pincer grasp).
- Pushing buttons and rolling balls help figure out how things work.
- Activities/books/songs/rhymes with repetition are fun, predictable, and help to build memory.
- Your baby can imitate speech by babbling consonant sounds (“bababa” or “datada”) and actions such as waving “bye-bye”. You can help your baby “speaking” by providing words for her emotions and pictures/objects your child is interested in.
- Your baby understands that things still exist even if they cannot see them making “hide-and-seek” more run, and “good-byes” even harder. Remember, never sneak out. Your babies awareness may cause them to be clingy with their caregivers and more fearful with strangers. Providing comfort is soothing, not “spoiling”.
- Face-to-face interaction with caregivers and avoiding screen time, except for live video chatting with loved ones, will enhance your child’s social and verbal development.
Family Well-being
- Nine month olds are developing opinions, strong feelings, and expectations that can lead to frustration and upset. Sometimes infants can be calmed by distraction, sometimes they need to be held, or sometimes talking to them calmly can help. This is normal, though can be exhausting for caregivers. It is OK to take time for yourself.
- Consider letting your baby stay with someone you trust in order to find time for yourself or to reconnect with your partner/friends.
Infant Care
** Acetaminophen and ibuprofen can help with fever and signs of discomfort. ** Teething rings, a cool washcloth, or a clean finger can be used to baby’s gums during times of teething discomfort. Brush teeth twice daily with fluoride toothpaste the size of a grain of rice on a soft toothbrush or clean finger. Avoid teething products with benzocaine. ** It is safe to take your baby outdoors if they are dressed appropriately and protected from the weather. Be cautious about exposing your baby to crowds or to people who may be sick. ** Use sunscreen (SPF 15 or higher). ** Saline drops can be used for nasal congestion, which is common in infants.
Sleep
- Simple, calming, bedtime routines can help prepare your baby for bedtime. Try to recognize signs that your baby is getting tired.
- Help your baby learn how to fall asleep on their own by putting them down when they are drowsy, but not fully asleep. Expect a protest if this is a new change for your child.
- Some babies establish a pattern of naps with long stretches of sleep, but others are fine taking shorter naps or napping at less regular times. Recognizing patterns and create a nap ritual can be helpful. Nap patterns will change as your baby grows and develops.
- Anticipate sleep disruption as part of normal development.
- A favorite stuffed animal may help your baby feel more secure.
Nutrition
- Your baby is transitioning from breast milk and formula to solids as the main source of nutrition and calories.
- Give Vitamin D (400IU/day) to babies receiving break milk.
- Continue simple routines including 3 meals (fruits, veggies, meats/proteins, grains) a day. Meals are opportunities to spend time together as a family.
- Your baby may be ready for more thickness and lumpiness of their food. Your child may also be ready to feed themselves with your support.
- Finger foods are bit size, easy to pick up, and squish between fingers. Avoid foods that may cause choking.
- Let your baby decide how much food to have and how fast/slow to eat it. Give your baby time to pause, rest, socialize, and go back to eating. Talking in a relaxed/encouraging manner helps you and your baby feel calm. It is normal for feedings to be messy.
- Offer a cup without “no-spill valve”. Your baby does not need juice, tea, or flavored drinks. Avoid honey.
Overseas Travel
If you will be traveling with your family overseas, talk with your doctor about travel questions, or you can request an online pre-travel health consultation through our eTravel Clinic. Visit our website to learn more.
-
Baby Wellness Guide at 2 Months Old
Helpful tips for this state of life.
Infant Care
- For babies 3 month or younger, a fever can be serious. Call us if your baby has a temperature of 100.4 F / 38.0 C or higher.
- It is safe to take your baby outdoors if they are dressed appropriately and protected from the weather. Be cautious about exposing your baby to crowds or to people who may be sick.
- Caregivers can further protect their baby by updating their own vaccinations, especially the Tdap (whooping cough vaccine), MMR, and seasonal flu vaccine.
- Saline drops and suction can be used for nasal congestion, which is common in infants.
Family Well-being
- Simple routines and schedules can give you and your baby a sense of confidence regarding expectations during your day.
- Try to find moments in your day to care for yourself in a healthy way. When you are calm and relaxed, your baby is also more likely to feel calm.
- Ask for help from trusted family and friends so you can get a break yourself.
- Finding nurturing and safe childcare can help you feel more comfortable during the times you might need to be away from your baby.
Development
- Your baby is recognizing and responding to caregivers, and enjoys smiling at you and seeing your delight. Babies can focus on and start to track caregivers and objects/toys. They may start to coo and take turns “talking”. Your baby prefers you over any toy/object.
- Babies at this age are learning how to self soothe by sucking on a pacifier or a finger. They are able to practice being on their tummy while looking at you, a mirror, or a toy.
- Your baby may also express their personality by showing preferences for toys, activities, and what schedule works for them.
- Acknowledge your baby’s preferences so they feel understood. Recognize when they are alert and ready to play. If they are crying, turning away, and arching, your baby is signaling you to slow down or provide comfort. Being warm and affectionate may seem easy when your baby is happy, but it is also important to provide responsive and loving care when they are fussy and crying. This lets your baby know they are loved, understood, and not alone.
- Everyday interactions like feeding, dressing, and diaper changing are opportunities to share loving and caring messages with your baby. By providing responsive and nurturing care, you are not “spoiling” them.
- Face-to-face interaction with caregivers and avoiding screen time, except for live video chatting with loved ones, will enhance your child’s social and verbal development.
Nutrition
- Use breast milk and formula only.
- Give Vitamin D (400 IU/day) to babies receiving break milk.
- You are learning your baby’s signals (sounds, facial expressions, and baby movements) to know when you’re hungry or full.
- Feeding can be an opportunity to cuddle, talk to, and enjoy your baby.
- Spitting up is common. Keeping your baby upright after feeds can help. Ask your doctor if you have concerns about associated pain, choking, or feeding problems.
Sleep
- Consider starting simple, calming routines to help your baby prepare for bedtime. It can be helpful to recognize signs that your baby is getting tired in order to know when to slow down and start your sleep routine.
- Some babies at this age are able to learn how to fall asleep after being put down when drowsy, but not fully asleep.
- You can help your baby sleep at night by not waking them to feed and by keeping the room dark and quite.
Safety
- Put your baby to sleep on their back. Sleep positioners are not safe for babies.
- Install the car seat in backseat, rear-facing.
- Check to make sure smoke and carbon monoxide detectors are working.
- Avoid smoke/tobacco/cigarette/vaping liquid or smoke/marijuana exposure.
- Avoid hot liquids around your baby and set your water temperature < 120 F (48.9 C) to prevent accidental burns.
- Avoid strings or necklaces around the neck as they can choke a baby.
- A baby can roll or fall off of a high surface. Keep a hand on him when changing clothes and/or diapers.
- Babies need constant supervision when bathing.
- Never shake your baby. When you are feeling overwhelmed, take a break and ask for help. Call Allegro Pediatrics for support.
Overseas Travel
If you will be traveling with your family overseas, talk with your doctor about travel questions, or you can request an online pre-travel health consultation through our eTravel Clinic. Visit our website to learn more.
-
A Case Study of Google Spreadsheet Script
Problem
I would like to port the data of the following table on https://www.etf.com/stock/FB into Google Spreadsheet using a programmatic manner.
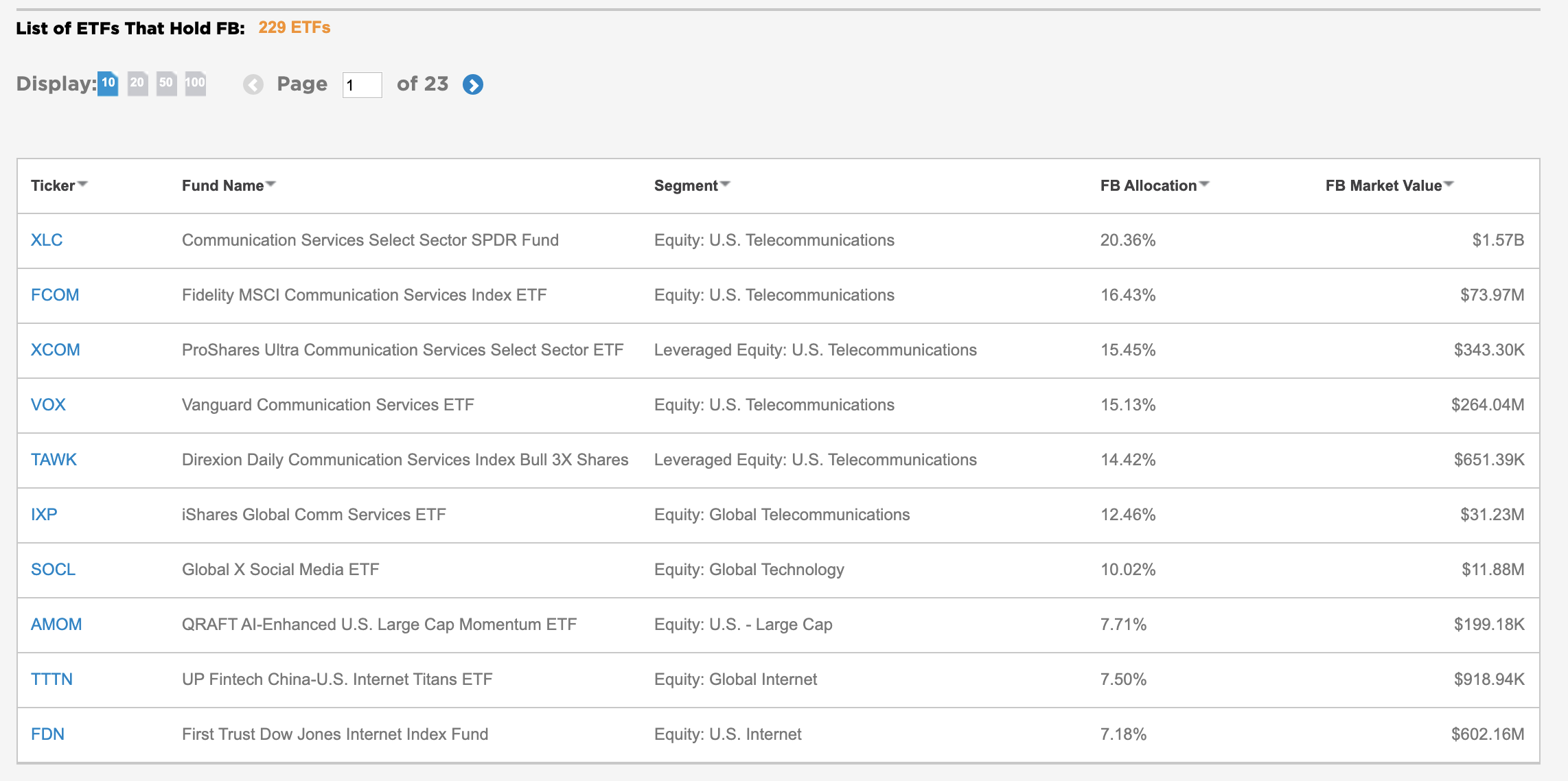
I have tried Google’s built functions
IMPORTHTMLandIMPORTXML, but they do not work as expected. The former can extract some lists / tables, but the target one is missed. For the latter, I tried to query the element using filter like//table[@id='xxx'], wherexxxis the id I obtained from Inspect tool, but failed again. I suspect this is because that table is dynamically generated using some js function.Solution
By inspecting the page source, it looks like the table data is driven by the following div element, where the giant
base64Dataattributes seems to contain promising information.<div id="etf-finder-results" data-react='{"page": "stock", "fundsTotal": "229", "tableTitle": "List of ETFs That Hold FB", "base64Data": "W3siY29sXzEiOiJUaWNrZXIiLCJjb2xfMiI6IkZ1bmQgTmFtZSIsImNvbF8zIjoiU2VnbWVudCIsImNvbF80IjoiRkIgQWxsb2NhdG...After decoding, I was able to obtain the original json string of the entire table! I tried to
curlthe url immediately and verified that the same base64 string can be retrieved.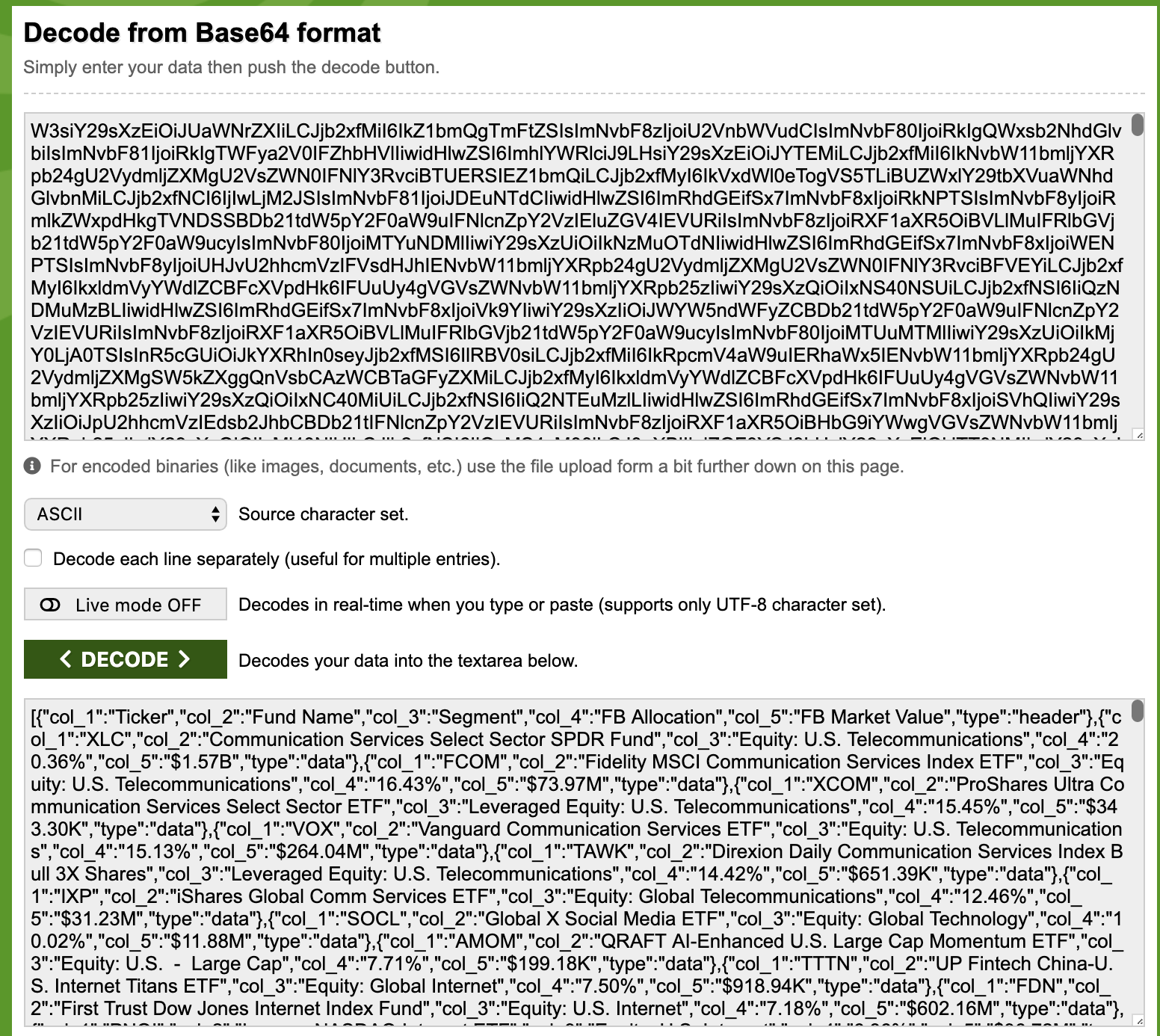
-
[LeetCode 1442] Count Triplets That Can Form Two Arrays of Equal XOR
- The Question
- O(n^4)-time solution [TLE]
- O(n^3)-time solution [AC]
- O(n^2)-time solution [AC]
- Yet another O(n^2)-time solution [AC]
- O(n)-time solution [AC, Optimal]
The Question
Given an array of integers
arr. We want to count number of indicesi,jandkwhere (0 <= i < j <= k < arr.length) such asarr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]is equal toarr[j] ^ arr[j + 1] ^ ... ^ arr[k].O(n^4)-time solution [TLE]
Just doing brute-force to enumerate
i,jandk, and another loop to check the xor values in both subarrays.class Solution: def countTriplets(self, arr: List[int]) -> int: n = len(arr) ans = 0 for i in range(n): for j in range(i+1, n): for k in range(j, n): a = b = 0 for l in range(i, j): a ^= arr[l] for l in range(j, k+1): b ^= arr[l] ans += 1 if a == b else 0 return ansO(n^3)-time solution [AC]
We can optimize the above solution by preprocessing all the prefix-xor values, then the xor value for any subarray can be computed in O(1) time.
class Solution: def countTriplets(self, arr: List[int]) -> int: n = len(arr) ans = 0 prefix = list(arr) for i in range(1, n): prefix[i] ^= prefix[i - 1] for i in range(n): for j in range(i+1, n): for k in range(j, n): a = prefix[j - 1] ^ prefix[i] ^ arr[i] b = prefix[k] ^ prefix[j - 1] ans += 1 if a == b else 0 return ansO(n^2)-time solution [AC]
Instead of doing nested for-loops for all
i,jandk, we can enumeratejfirst to determine the boundary of the two subarrays. Then we can enumerate (say) all the left boundaryiof the left subarray and count different xor values using a dictionary. Finally we can enumerate the right boundarykof the right subarray and count all the xor values that appeared before.from collections import Counter class Solution: def countTriplets(self, arr: List[int]) -> int: n = len(arr) ans = 0 for j in range(1, n): xor = 0 counter = Counter() for i in range(j - 1, -1, -1): xor ^= arr[i] counter[xor] += 1 xor = 0 for k in range(j, n): xor ^= arr[k] ans += counter[xor] return ansYet another O(n^2)-time solution [AC]
The fact that
arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]is equal toarr[j] ^ arr[j + 1] ^ ... ^ arr[k]implies thatarr[i] ^ ... ^ a[k] = 0. On the other hand, ifarr[i] ^ ... ^ a[k] = 0, we can produce exactlyk - iunique triplets. Therefore, we can enumerate all the subarrays (of length >= 2) that have xor value equal to 0 and do the counting accordingly.class Solution: def countTriplets(self, arr: List[int]) -> int: n = len(arr) ans = 0 xor = 0 for i in range(n): xor = arr[i] for j in range(i + 1, n): xor ^= arr[j] if xor == 0: ans += j - i return ansO(n)-time solution [AC, Optimal]
We can further optimize the runtime of the above solution to O(n). Note that
arr[i] ^ ... ^ a[k] = 0is equivalent toarr[0] ^ ... ^ arr[i-1] = arr[0] ^ ... ^ arr[k]. Therefore, # of unique triplets whenkis fixed issum_s(k - s - 1)for all0 <= s < ksuch thatarr[0] ^ ... ^ arr[s] = arr[0] ^ ... ^ arr[k]. We can rearrangesum_s(k - s - 1)assum_s(k-1) - sum_s(s). It follows that we just need to maintain (using two dictionaries) two values (count and index sum) for each distinct prefix xor while doing the prefix scan.from collections import Counter class Solution: def countTriplets(self, arr: List[int]) -> int: ans = 0 # Add a dummy entry for xor = 0 with index = -1 and cnt = 0. xor_index_sum = Counter({0:-1}) xor_cnt = Counter({0:1}) xor = 0 for i in range(len(arr)): xor = xor ^ arr[i] if xor_cnt[xor] > 0: ans += xor_cnt[xor] * (i - 1) - xor_index_sum[xor] xor_index_sum[xor] += i xor_cnt[xor] += 1 return ans
- 2024-01-05 美国入关记
- ChatGPT helps write an email for garbage bin replacement
- How to merge and extract tgz files from Google Takeout?
- How to auto-reload all the modules and classes in Python Notebook?
- How to hide WPM box in Typeracer?
- How to Skip Duplicate Files on Mac
- Xfinity Internet does NOT come with UNLIMITED data for free
- Union in SQL
- Baby Wellness Guide at 9 Months Old
- Baby Wellness Guide at 2 Months Old